StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation
Akio Kodaira*, Chenfeng Xu*, Toshiki Hazama*, Takanori Yoshimoto, Kohei Ohno, Shogo Mitsuhori, Soichi Sugano, Hanying Cho, Zhijian Liu, Kurt Keutzer. [Paper] [Code] 8K star 🔥 😯 Try it!!💪
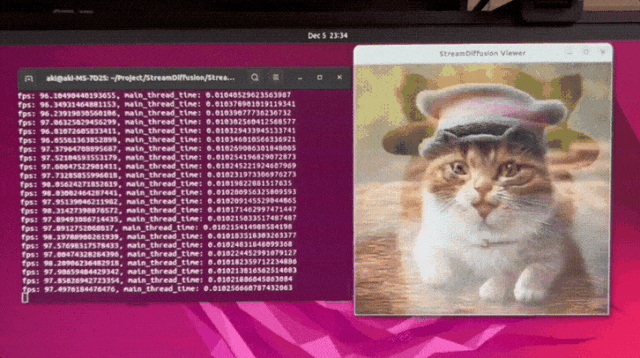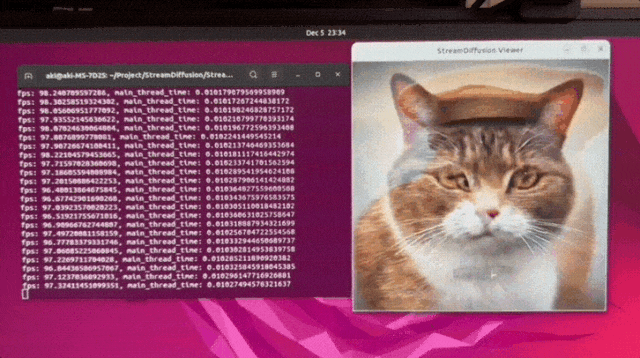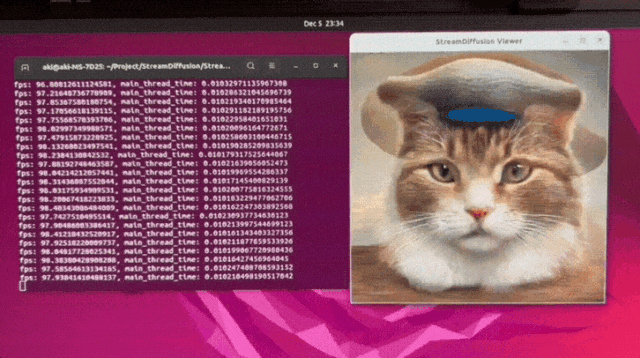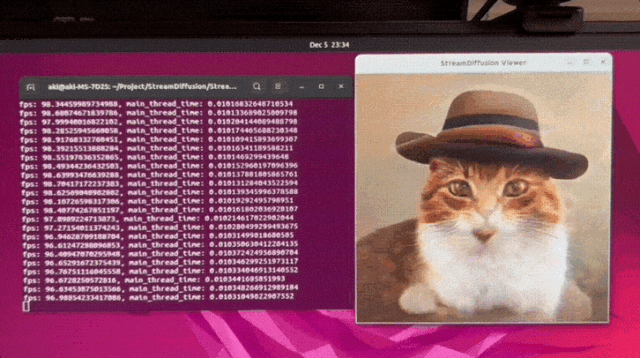
We make the diffusion process achieve extremely high throughputs and very low power usage 😊. We design the strategies like Stream Batch, Residual CFG, and Stochastic Similarity Filtering. Our StreamDiffusion pipeline can integrate existing efficient diffusion models. Feel free to check it in our page!
Efficient Temporal-3D Representation Learning for Generation, Perception, and Planning
Mirage: Cross-Embodiment Zero-Shot Policy Transfer with Cross-Painting
Lawrence Yunliang Chen*, Kush Hari*, Karthik Dharmarajan*, Chenfeng Xu, Quan Vuong, Ken Goldberg
[Website]
This is a surprisingly simple idea😄! X-paint the robot (or gripper) with the source robot (gripper) in images, then the visual policy can directly transfer really well!

3DiffTection: 3D Object Detection with Geometry-aware Diffusion Features
Chenfeng Xu, Huan Ling, Sanja Fidler, Or Litany. [Project page] CVPR 2024
Can StableDiffusion model work for 3D detection? 🤔️
🙋♂️ Hmm, maybe yes? But it is hard because it lacks 3D awareness. We incorporate 3D awareness into 2D stablediffusion model via a geometric controlnet.

NeRF-Det: Learning Geometry-Aware Volumetric Representations for Multi-View Indoor 3D Object Detection
Chenfeng Xu, Bichen Wu, Ji Hou, Sam Tsai, Ruilong Li, Jialiang Wang, Wei Zhan, Zijian He, Peter Vajda , Kurt Keutzer, Masayoshi Tomizuka. [ICCV 2023]. [Code]
The paper is featured as top 5 ICCV papers in Meta AI! [Link] 🎉
CV4Metaverse workshop (oral🎉) at ICCV 2023.
Does NeRF only work for 3D reconstruction? 🤔️
🙋♂️NeRF-Det makes a novel use of NeRF to build geometry-aware volumetric representations for 3D detection, with large improvement while eliminating the heavy overhead of per-scene optimization.

What Matters to You? Towards Visual Representation Alignment for Robot Learning
Ran Tian, Chenfeng Xu, Masayoshi Tomizuka, Jitendra Malik, Andrea Bajcsy. Accepted by ICLR 2024. [Paper]
How can we align visual representations to human preferences? 🤔️
🙋♂️In this work, we propose that robots should leverage human feedback to align their visual representations with the end-user and disentangle what matters for the task. We propose Representation-Aligned Preference-based Learning (RAPL), a method for solving the visual representation alignment problem and visual reward learning problem through the lens of preference-based learning and optimal transport.


Quadric Representations for LiDAR Odometry, Mapping, and Localization
Chenfeng Xu*, Chao Xia*, Patrick Rim, Mingyu Ding, Nanning Zheng, Kurt Keutzer, Masayoshi Tomizuka, and Wei Zhan. [RA-Letter 2023]
How to represent a point-cloud scene with thousands of points in an efficient manner? 🤔️
🙋♂️ You only need several quadrics. We propose quadric representations to describe the complex point-cloud scenes in LiDAR odometry, mapping and localization. Such a sparse representation enables better odometry accuracy, 3x faster mapping speed and 1000x less localization storage.

Open-Vocabulary Point-Cloud Object Detection without 3D Annotation
Chenfeng Xu*, Yuheng Lu*, Xiaobao Wei, Xiaodong Xie, Masayoshi Tomizuka, Kurt Keutzer, Shanghang Zhang. [CVPR 2023][Code]
Can point-cloud detectors be trained without 3D labels? 🤔️
🙋♂️ Image domain has shown great generalizablities in 2D foundation models. We address open-vocabulary 3D point-cloud detection by leveraging the 2D foundation models such as CLIP.

Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Google, Chenfeng Xu et al. ICRA 2024. [paper][project page]
I am proud to be part of this project! 🎉 Learning generalizable representations is not only important for vision tasks, but also for robot learning.
Check RT-X! It is a joint work from worldwide collaborators!

Time will tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection
Chenfeng Xu*, Jinhyung Park*, Shijia Yang, Kurt Keutzer, Kris Kitani, Masayoshi Tomizuka, Wei Zhan
[ICLR 2023 (Notable 5%)][Code]
Is temporal multi-view 3D detection able to run in an efficient way? 🤔️
🙋♂️ We theoretically analyze the effect brought by time frames, image resolutions, camera rotations and translations etc. We find that long-term frames can compensate for the lack of resolutions. We propose to generate a cost volume from a long history of image observations, compensating for the coarse but efficient matching resolution with a more optimal multi-view matching setup.

Image2Point: 3D Point-Cloud Understanding with 2D Image Pretrained Models
Chenfeng Xu∗, Shijia Yang∗, Tomer Galanti, Bichen Wu, Xiangyu Yue, Bohan Zhai, Wei Zhan, Peter Vajda, Kurt Keutzer, Masayoshi Tomizuka
[ECCV 2022] [Code]
This is a surprising work 😯!
Image and point-cloud have huge domain gap given that images are dense RGB arrays while point-clouds are sparse xyz points. We surprisingly found that image-pretrained model can be efficiently (300x fewer tuned parameters) tuned for point-cloud tasks. We also shed light on why it works through neural collapse, i.e., image-pretrained models present neural collapse in point-cloud.

DetMatch: Two Teachers are Better Than One for Joint 2D and 3D Semi-Supervised Object Detection
Jinhyung Park, Chenfeng Xu (Corresponded), Yiyang Zhou, Masayoshi Tomizuka, Wei Zhan
[ECCV 2022] [Code]
This is a useful autolabeling tool for 2D-3D object detection!
We propose DetMatch, a flexible framework for joint semi-supervised learning on 2D and 3D modalities. By identifying objects detected in both sensors, our pipeline generates a cleaner, more robust set of pseudo-labels that both demonstrate stronger performance and stymies single-modality error propagation.

PreTraM: Self-Supervised Pre-training via Connecting Trajectory and Map
Chenfeng Xu*, Tian Li*, Chen Tang, Lingfeng Sun, Kurt Keutzer, Masayoshi Tomizuka, Alireza Fathi, Wei Zhan
[ECCV 2022] [Code]
Why is this work the first to pre-train for trajectory forecasting? 😯
Trajectory data is too scarce to lift trajectory forecasting model data-efficient from pre-training. We open up a new path by leveraging hundreds of map data and connecting the trajectory representations to strong map representations. We associate geometric representations of maps and shapes of trajectories, which boosts the performance of trajectory forecasting. We then extend this into synthetic data. See Pre-Training on Synthetic Driving Data For Trajectory Prediction.


SqueezeSegV3: Spatially-adaptive Convolution for Efficient Point-cloud Segmentation
Chenfeng Xu, Bichen Wu, Zining Wang, Wei Zhan, Peter Vajda, Kurt Ketuzer, Masayoshi Tomizuka
[ECCV 2020] [Code]
Traditional convolutions are not suitable for point-cloud processing! Point-cloud map does not enable the convolution to learn inductive bias since different locations have totally different distributions. See our paper for a comprehensive analysis. We propose spatially-adaptive convolution to deal with it.

Human-oriented Representation Learning for Robotic Manipulation
Mingxiao Huo, Mingyu Ding, Chenfeng Xu, Thomas Tian, Xinghao Zhu, Yao Mu, Lingfeng Sun, Masayoshi Tomizuka, Wei Zhan
[Paper][Website]
How can we train a vision model more suitable for robotic learning? 🤔️
🙋♂️ Train it like training a human! We formalize this idea through the lens of human-oriented multi-task fine-tuning on top of pre-trained visual encoders, where each task is a perceptual skill tied to human-environment interactions. We introduce Task Fusion Decoder as a plug-and-play embedding translator that utilizes the underlying relationships among these perceptual skills to guide the representation learning towards encoding meaningful structure for what’s important for all perceptual skills, ultimately empowering learning of downstream robotic manipulation tasks.


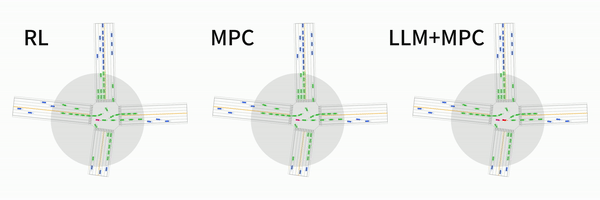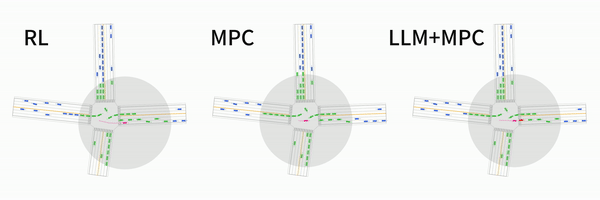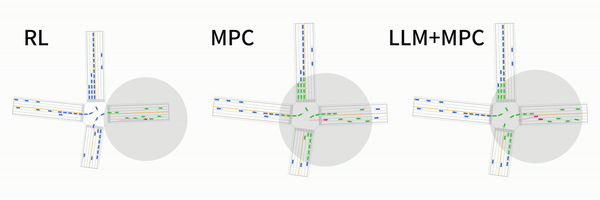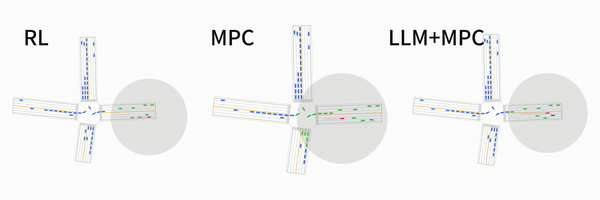
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving
Hao Sha, Yao Mu, Yuxuan Jiang, Li Chen, Chenfeng Xu, Ping Luo, Shengbo Eben Li, Masayoshi Tomizuka, Wei Zhan, Mingyu Ding
[Paper] [Website]
It is a cute idea of using LLM for AVs! We propose to use LLM to estimate the coefficiency of MPC! See the demo!